
lms-intrinsics is a package that enables the use of SIMD x86 instructions in the Lightweight Modular Staging Framework (LMS). While most SIMD instruction are available as a low-level machine code, the lms-intrinsics package focuses on the C SIMD instrinsics, which are supported by most modern C compilers such as gcc, Intel Compiler, LLVM, etc, and provides the appropriate generation of a vectorized C code.
Currently the following instruction sets (ISAs) are supported: MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, AVX-512, FMA, KNC and SVML. Each SIMD intrinsic function is implemented as a construct of an Embedded Domain Specific Language (eDSL) in LMS. The intrinsics functions are then categorized according to their ISA and are implemented in separate groups of SIMD eDSLs such that each eDSL corresponds to a particular ISA.
This implementation of LMS Intrinsics is done by Ivaylo Toskov as part of a master thesis project at the Department of Computer Science at ETH Zurich Switzerland, supervised by Markus Püschel and me. This work has been published at CGO’18, obtaining all 4 badges of the conference: Artifacts Available, Artifacts Functional, Results Replicated and Artifacts Reusable.




Usage
lms-intrinsics is available on Maven and can be used through SBT including the following in build.sbt:
libraryDependencies += "ch.ethz.acl" %% "lms-intrinsics" % "0.0.5-SNAPSHOT"
A detailed explanation of the usage and a quick start tutorial can be found on the GitHub repository.
Automatic Generation of SIMD eDSLs
There is a vast majority of SIMD instructions available in a given CPU. With the continuous development of the x86 architecture, Intel has extended the instruction set architecture with many new sets, continuously adding more vector instructions. As a result creating eDSLs aming to support majority of intrinsics functions, is not an easy challenge. The figure bellow gives an overview of available intrinsics function for each instruction set architecture:
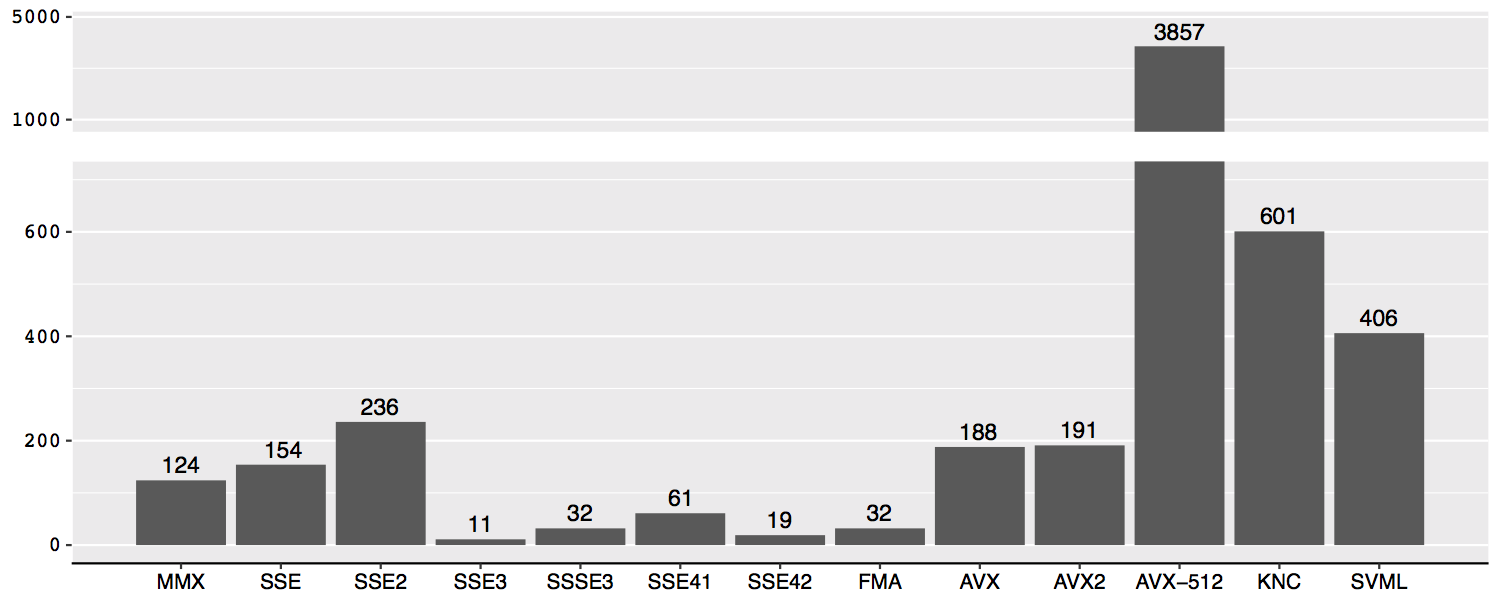
As depicted on the image there are mote than 5000 functions that have to be ported into several eDSLs. Doing this manually is a
tedious and an error prone process. To avoid this, we decided to automate the generation of these SIMD eDSLs. A good place to
start is the Intel Intrinsics Guide which provides the specifications
of each C intrinsic function. Observing this website, we noticed that it comes with a nice and convenient XML file that provides
the name, return type and input arguments of each intrinsic function:
<intrinsic rettype='__m256d' name='_mm256_add_pd'>
<type>Floating Point</type>
<CPUID>AVX</CPUID>
<category>Arithmetic</category>
<parameter varname='a' type='__m256d'/>
<parameter varname='b' type='__m256d'/>
<description>
Add packed double-precision (64-bit)
floating-point elements in "a" and "b",
and store the results in "dst".
</description>
<operation>
FOR j := 0 to 3
i := j*64
dst[i+63:i] := a[i+63:i] + b[i+63:i]
ENDFOR
dst[MAX:256] := 0
</operation>
<instruction name='vaddpd' form='ymm, ymm, ymm'/>
<header>immintrin.h</header>
</intrinsic>
As a result, we wer able to create a generator that will take each XML entry and produce Scala code tailored for the LMS framework that corresponds for each intrinsics functions:
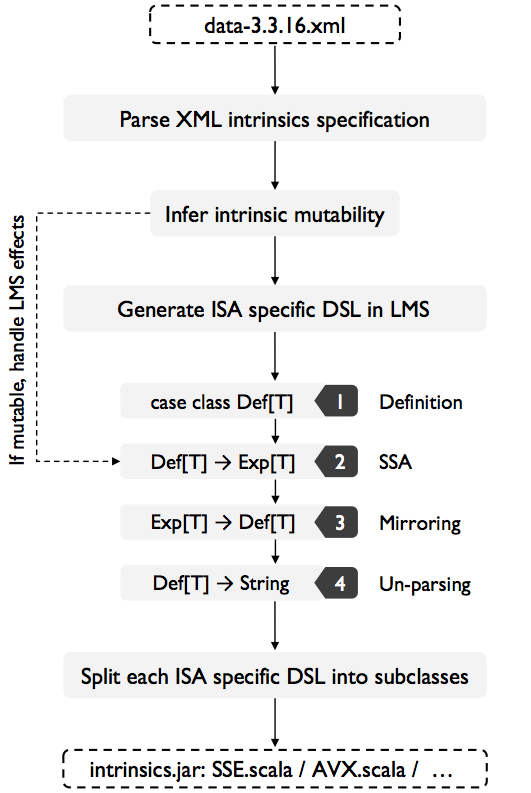
This process was quite convenient, as most intrinsics functions are in fact immutable and produce no effects. The generation is done in 4 steps. Step 1: Generation of definitions:
case class MM256_ADD_PD (a: Exp[__m256d], b: Exp[__m256d]) extends IntrinsicDef[__m256d] {
val category = List(IntrinsicsCategory.Arithmetic)
val intrinsicType = List(IntrinsicsType.FloatingPoint)
val performance = Map.empty[MicroArchType, Performance]
val header = "immintrin.h"
}
Step 2: Automatic SSA conversion (driven by LMS)
def _mm256_add_ps(a: Exp[__m256], b: Exp[__m256]): Exp[__m256] = {
MM256_ADD_PS(a, b)
}
Step 3: Mirroring (LMS default transformation step)
override def mirror[A:Typ](e: Def[A], f: Transformer)(implicit pos: SourceContext) = (e match {
case MM256_ADD_PS (a, b) => _mm256_add_ps(f(a), f(b))
// Pattern match against all other nodes
case _ => super.emitNode(sym, rhs)
}
Step 4: Unparsing to C
override def emitNode(sym: Sym[Any], rhs: Def[Any]) = rhs match {
case iDef@MM256_ADD_PS(a, b) =>
headers += iDef.header
emitValDef(sym, s"_mm256_add_ps(${quote(a)}, ${quote(b)})")
// Pattern match against all other nodes
case _ => super.emitNode(sym, rhs)
}
However, not all function are immutable, particularly load and store functions such as _mm256_loadu_ps or _mm256_storeu_ps. The Intel Intrinsics Guide however
includes parameter that depicts the category of each instruction. In fact it contains 24 categories, conveniently categorizing load and store instructions.
We were able to use this parameter to infer the intrinsic function mutability, and generate the proper LMS effects.
Another challenge was the limitations imposed by the JVM - the 64kB limit for a method. To avoid this issue, we develop the generator such that generates Scala code that is split into several sub-classes, constituting a class that represent an ISA by inheriting each sub-class.
The resulting Scala code is consisted of several Scala class files, that contain few thousands of lines of code that takes the Scala compiler several minutes to get compiled. To make the future use of this work more convenient, we decided to precompile the library, and make it available at Maven.
To learn more about this work, check out our paper SIMD Intrinsics on Managed Language Runtimes. For in-depth overview of the process of automatic generation of SIMD eDSLs, have a look at the master thesis work of Ivaylo titled Explicit SIMD instructions into JVM using LMS. Finally, you can also checkout the 20 minute video presentation at CGO which is followed by a short question and answer session.